pythonで文字列から音声ファイルを作ってみる

pythonで文字列から音声ファイルを作ってみる
題名の通りなのですが、「文字列」をpythonに読み込ませて「音声ファイル」を作成してみます。
「open_jtal」とかもあったんですがCentOSだと構築が大変そう且つ声が微妙だったので他を探していたら、「docomo」の「API」がありました。
車輪の発明ありがとうございます。
docomoのAPI取得申請
まずはAPIを取得します。
申請は下からお願いします。
・docomo Developer support へようこそ
登録手順は下を参考にしました。
・docomo雑談APIのAPIキーを発行する
ただ一つだけ情報が新しくなっていました。
APIの種類が増えたり名前が変更されているみたいですが今回作る機能だけの場合は下の画像のだけチェックを付ければ大丈夫です。
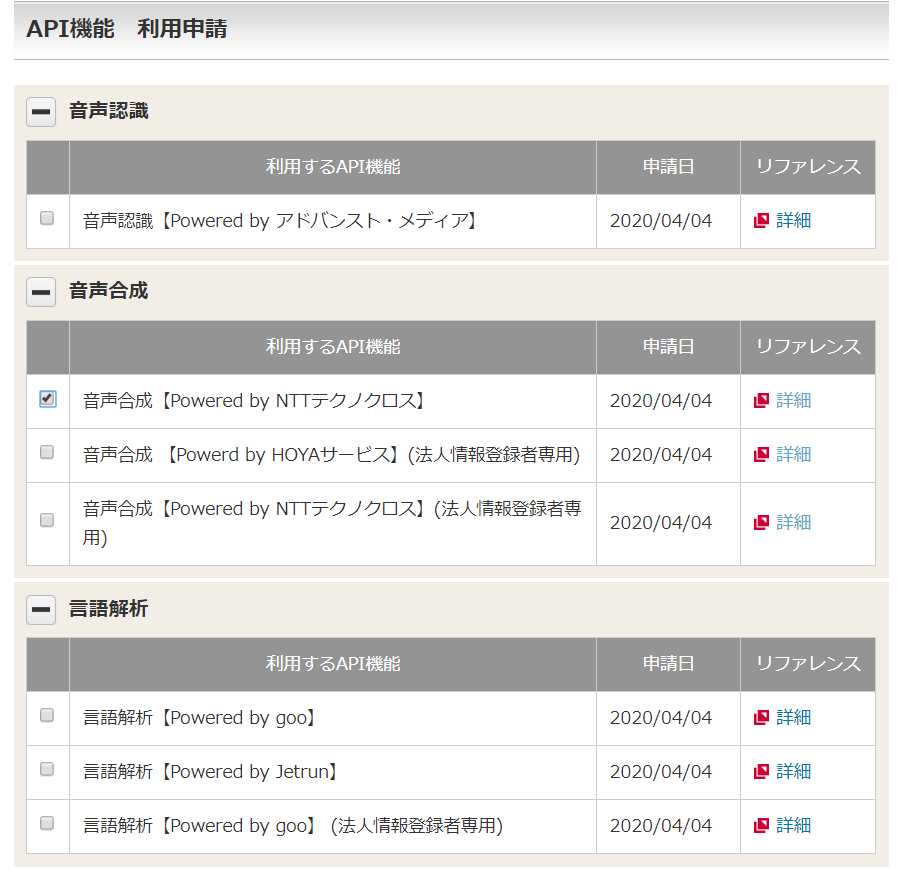
上記の手順通りに進めていくと「マイページ」に「API key」と記載されている項目があります。
この項目の「API key」をコピーしておきましょう
プログラム
あとはコーディングしていきます。
下の[API key]の部分は先ほどコピーした値になります。
url = 'https://api.apigw.smt.docomo.ne.jp/crayon/v1/textToSpeech?APIKEY=[API key]'
コード全体の構成は下の通りです。
import os
import requests
import json
url = 'https://api.apigw.smt.docomo.ne.jp/crayon/v1/textToSpeech?APIKEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
params = {
"Command":"AP_Synth",
"SpeakerID":"1",
"StyleID":"1",
"SpeechRate":"1.15",
"AudioFileFormat":"2",
"TextData":'生まれ変わったら開発がしたい'
}
request = requests.post(url, data=json.dumps(params))
if request.status_code == requests.codes.ok:
wav = request.content
with open("test.wav","wb") as file:
file.write(wav)
実行結果
実行すると「test.awv」と言うファイルが同階層に作成されます。
.
├── test.wav
└── text_to_voice.py
音声ファイルを再生してみましょう。
声質を変えたいときは「params」の値を変更するみたいです。
参考ページはこちら。