pythonに画像を読み込ませて喋る動画にしてみた

pythonに画像を読み込ませて喋る動画にしてみた
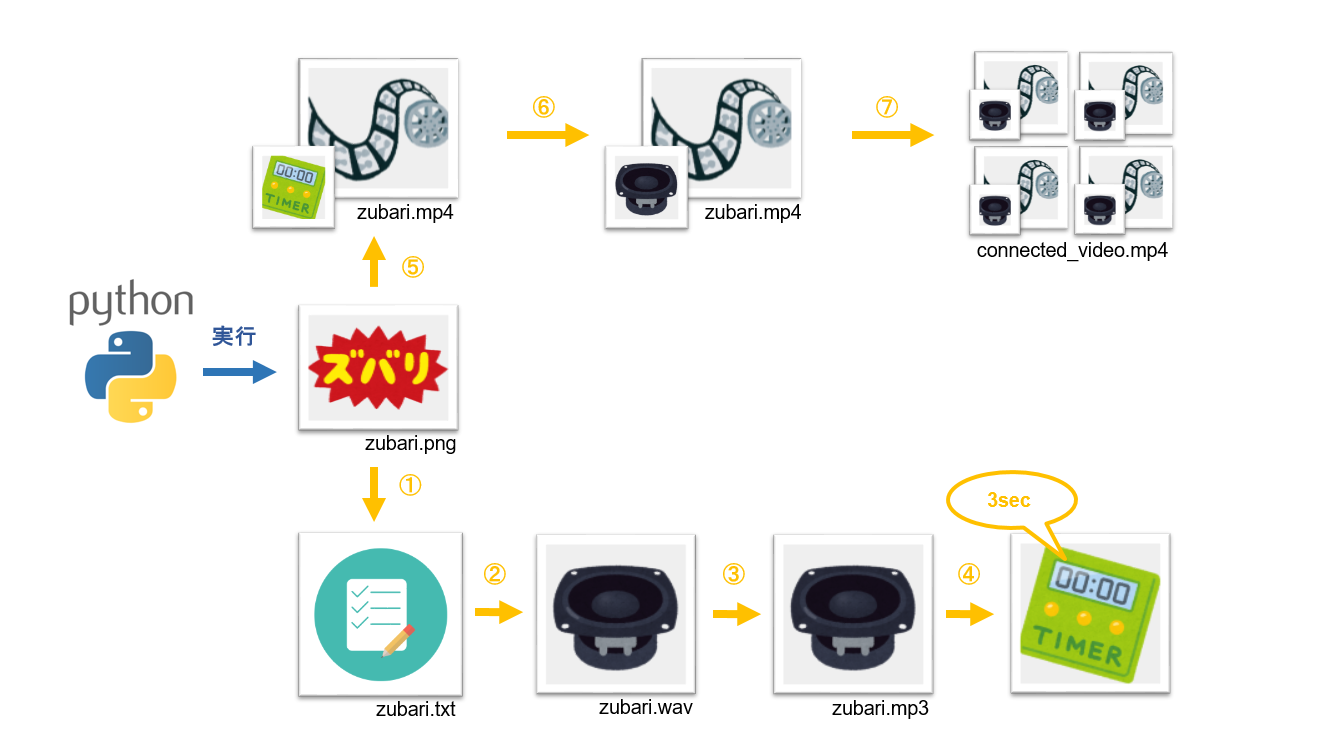
早速ですがプログラムは下のような手順で加工を行っております。
1.画像ファイルから文字列「ズバリ」を認識してテキストファイルを作成します。
2.テキストの「ズバリ」を読み込み音声ファイル「wav」を作成します。
3.音声ファイル「wav」から「mp3」形式のファイルを作成します。
4.音声ファイル「mp3」の再生時間を測定します。
5.「測定された音声ファイルの再生時間」を元に画像ファイルから動画ファイルを作成します。
6.作成された動画ファイルに音声ファイルを合成した動画ファイルを作成します。。
7.上記手順1~6で生成された複数の動画を結合して一つの動画ファイルを作成します。
※イメージは下の通りです。
階層
プログラム実行前の階層は下の通りです。
.
├── connected_video
├── picture
│ ├── comment_01.png
│ └── comment_02.png
├── sound_mp3
├── sound_wav
├── text
├── video
├── video_maker.py
└── video_with_sound
画像ファイル
「pictureディレクトリ」に対象となる画像を設置してください。
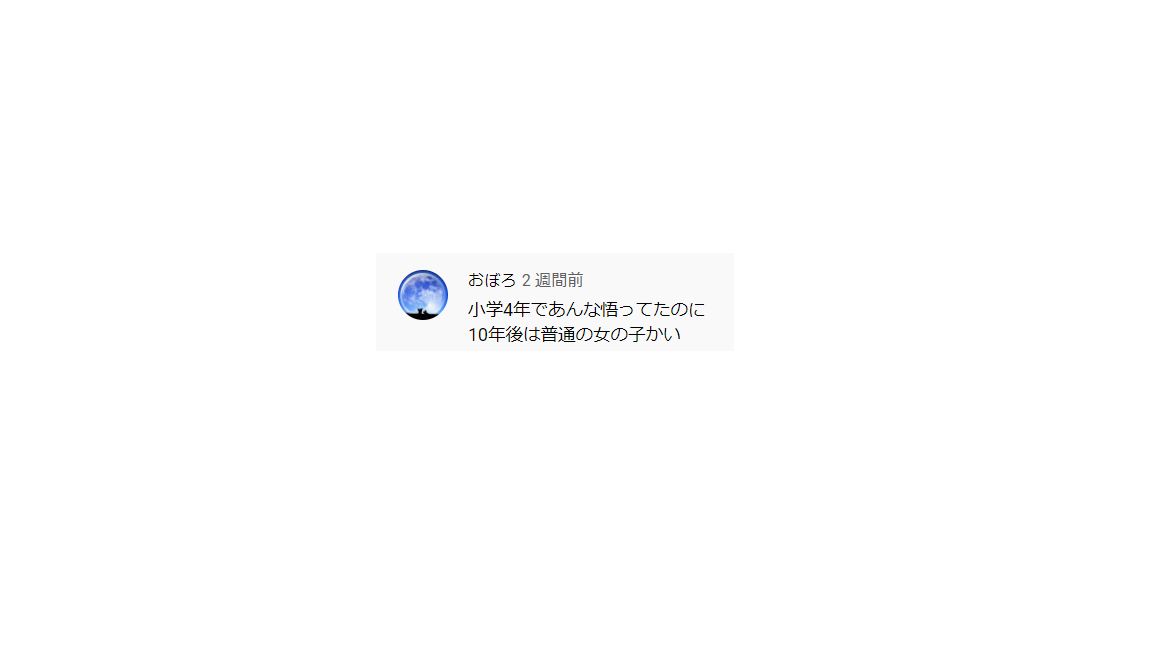
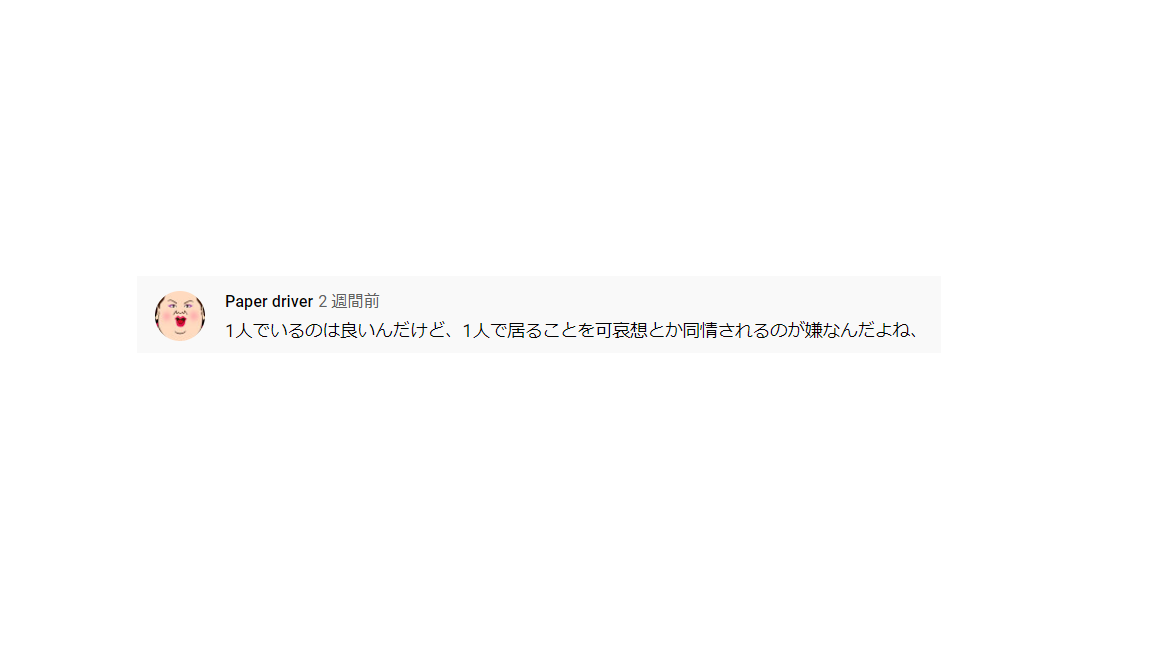
今回は下の2つのファイルを設置しました。
【comment_01.png】
【comment_02.png】
プログラム
# -*- coding: utf-8 -*-
#ファイル
import os
#画像
import pyocr
from PIL import Image
#音声
import requests
import json
import pydub
#動画
import cv2
import moviepy.editor as mp
class FileController:
def get_file_names(self, path):
file_names=os.listdir(path=path)
return file_names
class PictureController:
def __init__(self):
tools = pyocr.get_available_tools()
assert(len(tools) != 0)
self.tool = tools[0]
def picture_to_text(self, picture_file_names):
for picture_file_name in picture_file_names:
txt = self.tool.image_to_string(
Image.open('./picture/'+picture_file_name),
lang = 'jpn',
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
)
text_file_name = picture_file_name.replace('.png', '.txt')
with open('./text/'+text_file_name, 'wb') as file:
file.write(txt.encode('utf-8'))
def picture_to_video(self, sound_dicts):
for sound_dict in sound_dicts:
picture_file_name = sound_dict['file_name'].replace('.mp3', '.png')
video_file_name = sound_dict['file_name'].replace('.mp3', '.mp4')
sound_time = sound_dict['time']
if os.path.exists('./picture/'+picture_file_name):
video_time = 2
img = cv2.imread('./picture/'+picture_file_name)
width = img.shape[1]
height = img.shape[0]
fourcc = cv2.VideoWriter_fourcc('m','p','4', 'v')
video = cv2.VideoWriter('./video/'+video_file_name, fourcc, 20.0, (width, height))
frame_count = video_time * 20
for num in range(frame_count):
video.write(img)
video.release()
else:
continue
class SoundController:
def __init__(self):
self.url = 'https://api.apigw.smt.docomo.ne.jp/crayon/v1/textToSpeech?APIKEY=xxxxxxxxxx'
def text_to_wav(self,text_dicts):
for text_dict in text_dicts:
params = {
"Command":"AP_Synth",
"SpeakerID":"1",
"StyleID":"1",
"SpeechRate":"2",
"AudioFileFormat":"2",
"TextData":text_dict['content']
}
request = requests.post(self.url, data=json.dumps(params))
if request.status_code == requests.codes.ok:
wav = request.content
wav_file_name = text_dict['file_name'].replace('.txt', '.wav')
with open('./sound_wav/'+wav_file_name ,"wb") as file:
file.write(wav)
def wav_to_mp3(self, wav_file_names):
for wav_file_name in wav_file_names:
sound = pydub.AudioSegment.from_wav('./sound_wav/'+wav_file_name)
mp3_file_name = wav_file_name.replace('wav', 'mp3')
sound.export('./sound_mp3/'+mp3_file_name, format='mp3')
def get_sound_seconds(self, mp3_file_names):
sound_dicts = []
for mp3_file_name in mp3_file_names:
sound_dict = {}
sound = pydub.AudioSegment.from_file('./sound_mp3/'+mp3_file_name, 'mp3')
sound_dict['file_name'] = mp3_file_name
sound_dict['time'] = sound.duration_seconds
sound_dicts.append(sound_dict)
return sound_dicts
class TextController:
def get_texts(self, text_file_names):
text_dicts = []
for text_file_name in text_file_names:
text_dict = {}
with open('./text/'+text_file_name, 'r', encoding='utf-8') as file:
text_dict['file_name'] = text_file_name
text_dict['content'] = file.read()
text_dicts.append(text_dict)
return text_dicts
class VideoController:
def combine_video_with_sound(self, video_file_names):
for video_file_name in video_file_names:
mp3_file_name = video_file_name.replace('.mp4', '.mp3')
if os.path.exists('./sound_mp3/'+mp3_file_name):
clip = mp.VideoFileClip('./video/'+video_file_name).subclip()
clip.write_videofile('./video_with_sound/'+video_file_name, audio='./sound_mp3/'+mp3_file_name)
else:
continue
def combine_video_with_video(self, video_with_sound_file_names):
clips = []
for video_with_sound_file_name in video_with_sound_file_names:
clip = mp.VideoFileClip('./video_with_sound/'+video_with_sound_file_name)
clips.append(clip)
final_clip = mp.concatenate_videoclips(clips)
final_clip.write_videofile('./connected_video/connected_video.mp4', fps=30)
def main():
#make instance
fileController = FileController()
pictureController = PictureController()
soundController = SoundController()
textController = TextController()
videoController = VideoController()
#make text from picture
picture_file_names = fileController.get_file_names('./picture/')
pictureController.picture_to_text(picture_file_names)
#make wav from text
text_file_names = fileController.get_file_names('./text/')
text_dicts = textController.get_texts(text_file_names)
soundController.text_to_wav(text_dicts)
#make mp3 from wav
wav_file_names = fileController.get_file_names('./sound_wav/')
soundController.wav_to_mp3(wav_file_names)
#make video from picture and sound_time
mp3_file_names = fileController.get_file_names('./sound_mp3/')
sound_dicts = soundController.get_sound_seconds(mp3_file_names)
pictureController.picture_to_video(sound_dicts)
#combine video and sound
video_file_names = fileController.get_file_names('./video/')
videoController.combine_video_with_sound(video_file_names)
#combine video and video
video_with_sound_file_names = fileController.get_file_names('./video_with_sound/')
videoController.combine_video_with_video(video_with_sound_file_names)
if __name__ == '__main__':
main()
実行結果
二枚目のアイコンのをなぜか「エム(?)」って発音しちゃってますね。