netkeiba.comから新着のデータのみスクレイピングしてデータベースにいれてみた
netkeiba.comから新着のデータのみスクレイピングする
競馬を分析するのが少々流行っているこの頃です。調べてみるとnetkeiba.comからデータを取得してきている記事を多く見ます。それにならい私も前回このような記事を書いてみましたが、今回は改良して下記の要件を加えてみました。
1.取得した値をデータベースに格納する
2.新着のデータのみスクレイピングする
3.slackに通知する
netkeiba.comのURLについて
netkeiba.comでスクレイピングするページのURLは下記のようになっています。
「https://race.netkeiba.com/race/result.html?race_id=202001020812&rf=race_list」
今回肝になってくるのはrace_idのパラメータですが、下記の規則で成り立っています。
race_id=開催年(NNNN年開催)+競馬場コード(競馬場NN)+開催回数(1年の内の開催N回目)+日数(開催の内のN日目)+レース数(1日の内のNレース目)
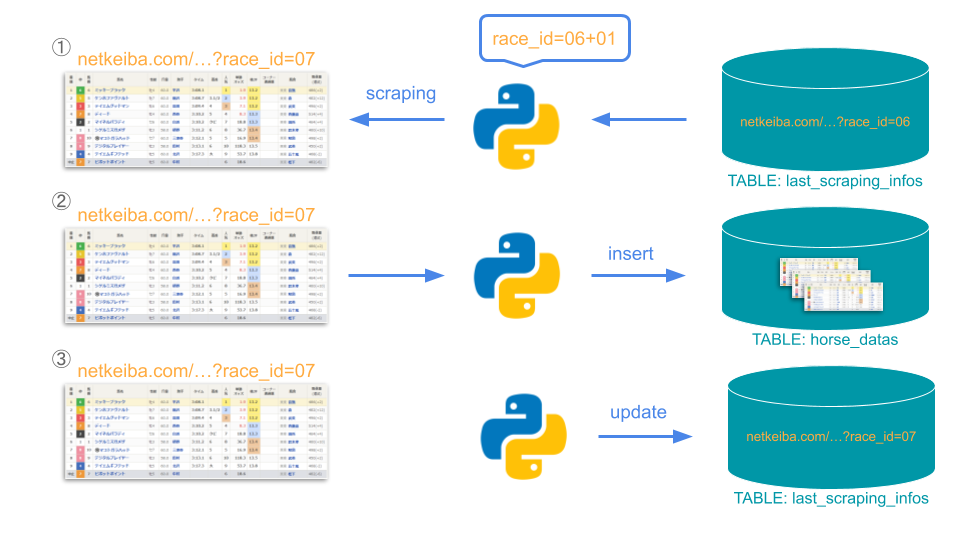
今回race_idをデータベースで管理することで「2」を実現しています。
まずスクレイピングを行い取得したデータのINSERTが成功した場合、該当するURLのパラメータをデータベースに保管します。次にプログラムが動く時は、「保管したパラメータのレース数に+1したURL」からスクレイピングを開始します。このロジックをコース毎に行います。
イメージは下の通りです。※厳密には+1ではなくcontinueです
コード
コードは下の通りです。
#%%
#--データベース------------------------------------------
import mysql.connector as mariadb
#--スクレイピング----------------------------------------
from bs4 import BeautifulSoup
import requests
import time
#--Slack-------------------------------------------------
import slackweb
#--データ分析--------------------------------------------
import pandas as pd
#--日付--------------------------------------------------
from datetime import date
#--エラー------------------------------------------------
import sys
import traceback
class ScrapingController():
def make_url(self, holding_year, race_course, holding_count, date_count, race_number):
race_id = [holding_year, race_course, holding_count, date_count, race_number]
race_id = [str(r) for r in race_id]
race_id = list(map(lambda x: x.zfill(2), race_id))
race_id = ''.join(race_id)
url = f'https://race.netkeiba.com/race/result.html?race_id={race_id}&rf=race_list'
return url
def get_horse_datas(self, url, holding_year, race_course, holding_count, date_count, race_number):
request = requests.get(url)
soup = BeautifulSoup(request.content, 'html.parser')
horses = soup.find_all(class_='HorseList')
horse_datas = []
for horse in horses:
horse_data = {}
#開催年(NNNN年開催)
#競馬場コード(競馬場NN)
#開催回数(1年の内の開催N回目)
#日数(開催の内のN日目)
#レース数(1日の内のNレース目)
horse_data['url'] = url
horse_data['holding_year'] = holding_year
horse_data['race_course'] = race_course
horse_data['holding_count'] = holding_count
horse_data['date_count'] = date_count
horse_data['race_number'] = race_number
horse_data['rank'] = horse.find(class_='Rank').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['horse_number'] = horse.find(class_='Txt_C').find('div').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['horse_name'] = horse.find(class_='Horse_Name').find('a').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_detail = horse.find(class_='Detail_Left').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['horse_sex'] = horse_detail[0] if len(horse_detail)==2 else ''
horse_data['horse_age'] = horse_detail[1] if len(horse_detail)==2 else ''
horse_data['jockey_weight'] = horse.find(class_='JockeyWeight').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['jockey_name'] = horse.find(class_='Jockey').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['race_time'] = horse.find(class_='RaceTime').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['popularity'] = horse.find(class_='OddsPeople').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['odds'] = horse.find(class_='Txt_R').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['passage'] = horse.find(class_='PassageRate').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_data['trainer'] = horse.find(class_='Trainer').find('a').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_weight = horse.find(class_='Weight').get_text().replace('\n','').replace(' ','').replace(' ','')
horse_weights = horse_weight.split('(')
horse_data['horse_weight'] = horse_weights[0] if len(horse_weights)==2 else ''
horse_data['horse_weight_changes'] = horse_weights[1].replace(')', '') if len(horse_weights)==2 else ''
horse_datas.append(horse_data)
time.sleep(1)
return(horse_datas)
class DatabaseController:
def __init__(self):
self.mariadb_connection = mariadb.connect(host='localhost', user='root', password='', database='netkeiba')
self.cursor = self.mariadb_connection.cursor(dictionary=True)
def insert_horse_datas(self, horse_datas):
for horse_data in horse_datas:
columns = ', '.join(horse_data.keys())
values = ', '.join(map(lambda x: f"'{x}'", horse_data.values()))
query = f'INSERT INTO horse_datas ({columns}) VALUES ({values})'
self.cursor.execute(query)
self.mariadb_connection.commit()
return True
def get_last_scraping_infos(self):
query = 'SELECT id, holding_year, race_course, holding_count, date_count, race_number FROM last_scraping_infos'
self.cursor.execute(query)
last_scraping_infos = list(self.cursor)
return last_scraping_infos
def update_last_scraping_info(self, holding_year, race_course, holding_count, date_count, race_number):
query = f'UPDATE last_scraping_infos SET holding_year = {holding_year}, holding_count = {holding_count}, date_count = {date_count}, race_number = {race_number} WHERE race_course = {race_course}'
self.cursor.execute(query)
self.mariadb_connection.commit()
return True
class SlackController:
def __init__(self):
self.slack = slackweb.Slack(url='https://hooks.slack.com/services/xxxxxxxxxx')
def notify_result(self, result_message):
text = result_message
self.slack.notify(text=text)
def notify_error(self, url, error_section, error_message):
text = f'============Error Occurred============\nURL:\n{url}\n\nセクション:\n{error_section}\n\nエラー内容:\n{error_message}\n===================================='
print(text)
self.slack.notify(text=text)
def main():
scrapingController = ScrapingController()
databaseController = DatabaseController()
slackController = SlackController()
last_scraping_infos = databaseController.get_last_scraping_infos()
next_year = date.today().year + 1
for last_scraping_info in last_scraping_infos:
print('#--FIRST_ROOP_OF_RACE_COURSE#-------------------------------------------------------------')
#コース毎の最初のループのルール
#1.コース毎に「続きからスクレイピングを開始する」為に最後に取得した情報を代入する
#2.重複を避ける為「最後に取得した情報」の次の値からスクレイピングを開始する
first_roop_of_race_course = True
race_course = last_scraping_info['race_course'] #1
holding_year_from = last_scraping_info['holding_year'] #1
holding_count_from = last_scraping_info['holding_count'] #1
date_count_from = last_scraping_info['date_count'] #1
race_number_from = last_scraping_info['race_number'] #1
for holding_year in range(holding_year_from, next_year):
for holding_count in range(holding_count_from, 11):
for date_count in range(date_count_from, 11):
print('------------------------------------------------------------------------------------------')
for race_number in range(race_number_from, 14):
if first_roop_of_race_course:
holding_year_from = 1
holding_count_from = 1
date_count_from = 1
race_number_from = 1
first_roop_of_race_course = False
continue #2
#分岐となるパラメータを初期化する
horse_datas = []
result_insert_horse_datas = False
result_update_last_scraping_info = False
#URLを生成する
url = scrapingController.make_url(holding_year, race_course, holding_count, date_count, race_number)
#スクレイピング開始する
try:
horse_datas = scrapingController.get_horse_datas(url, holding_year, race_course, holding_count, date_count, race_number)
except:
error_section = 'Scraping Horse Datas'
error_message = traceback.format_exc()
slackController.notify_error(url, error_section, error_message)
sys.exit()
#スクレイピングしたデータをデータベースに格納する
if horse_datas:
try:
result_insert_horse_datas = databaseController.insert_horse_datas(horse_datas)
except:
error_section = 'Insert Horse Datas'
error_message = traceback.format_exc()
slackController.notify_error(url, error_section, error_message)
sys.exit()
#最後にスクレイピングしたデータを記録する
if result_insert_horse_datas:
try:
result_update_last_scraping_info =databaseController.update_last_scraping_info(holding_year, race_course, holding_count, date_count, race_number)
except:
error_section = 'Update Last Scraping Info'
error_message = traceback.format_exc()
slackController.notify_error(url, error_section, error_message)
sys.exit()
#※ターミナル確認用
if result_update_last_scraping_info:
print(f'{url}: SUCCESS - {len(horse_datas)}')
else:
print(f'{url}: SKIP - {len(horse_datas)}')
slackController.notify_result('更新が完了しました。')
print('--DONE------------------------------------------------------------------------------------')
if __name__ == '__main__':
main()
最後に
これで今後データを取得する時はURLを指定してプログラムを実行しなくて済むようになりました。これならcronに任せられますし、エラーも通知が来るので一安心です。一応2万件取得してみましたが問題なく動いてくれています。